Abstract
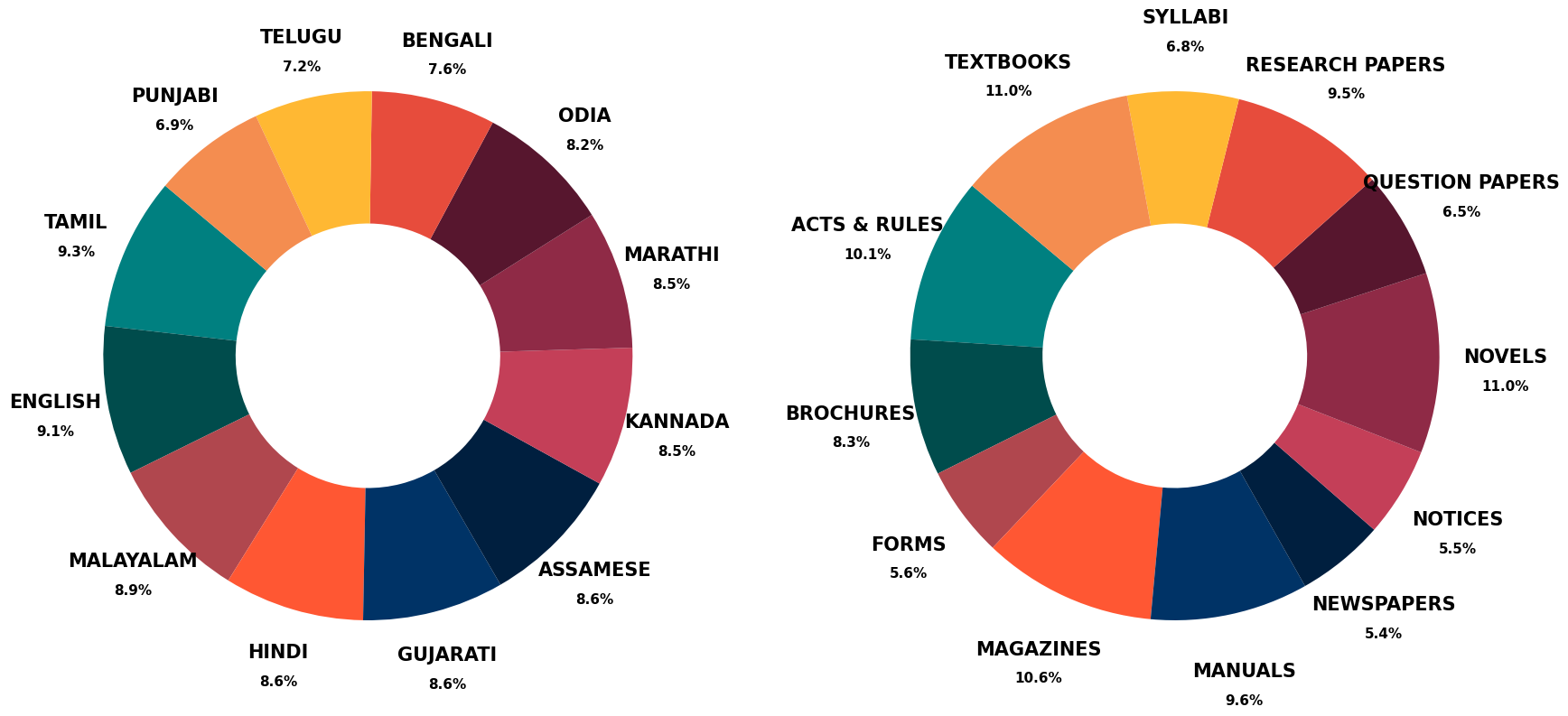
Document layout analysis is essential for downstream tasks such as information retrieval, extraction, OCR, and digitization. However, existing large-scale datasets like PubLayNet and DocBank lack fine-grained region labels and multilingual diversity, making them insufficient for representing complex document layouts. In contrast, human-annotated datasets such as M6Doc and D4LA offer richer labels and greater domain diversity, but are too small to train robust models and lack adequate multilingual coverage. This gap is especially pronounced for Indic documents, which encompass diverse scripts yet remain underrepresented in current datasets, further limiting progress in this space. To address these shortcomings, we introduce IndicDLP, a large-scale foundational document layout dataset spanning 11 representative Indic languages alongside English and 12 common document domains. Additionally, we curate UED-mini, a dataset derived from DocLayNet and M6Doc, to enhance pretraining and provide a solid foundation for Indic layout models. Our experiments demonstrate that fine-tuning existing English models on IndicDLP significantly boosts performance, validating its effectiveness. Moreover, models trained on IndicDLP generalize well beyond Indic layouts, making it a valuable resource for document digitization. This work bridges gaps in scale, diversity, and annotation granularity, driving inclusive and efficient document understanding.

(A) Acts & Rules

(B) Brochures

(C) Forms

(D) Magazines

(E) Manuals

(F) Newspapers

(G) Notices

(H) Novels

(I) Question Papers

(J) Research Papers

(K) Syllabi

(L) Textbooks
Samples from the IndicDLP dataset highlighting its diversity across document formats, domains, languages, and temporal span. For improved differentiability, segmentation masks are used instead of bounding boxes to highlight regions more effectively.
Comparison with Other Datasets
| Dataset | #Images | #Region Classes | Annotation Method | #Domains | #Languages |
|---|---|---|---|---|---|
| PRImA | 1,240 | 10 | Automatic | 5 | 1 |
| PubLayNet | 360,000 | 5 | Automatic | 1 | 1 |
| DocBank | 500,000 | 13 | Automatic | 1 | 1 |
| DocLayNet | 80,863 | 11 | Manual | 6 | 4 |
| M6Doc | 9,080 | 75 | Manual | 7 | 2 |
| D4LA | 11,092 | 27 | Manual | 12 | 1 |
| BaDLAD | 33,695 | 4 | Manual | 6 | 1 |
| IndicDLP (Ours) | 119,806 | 42 | Manual | 12 | 12 |
Comparison of modern document layout parsing datasets.
Citation
Please cite our paper if you find this dataset or work useful:
@InProceedings{10.1007/978-3-032-04614-7_2,
author="Nath, Oikantik
and Kukkala, Sahithi
and Khapra, Mitesh
and Sarvadevabhatla, Ravi Kiran",
editor="Yin, Xu-Cheng
and Karatzas, Dimosthenis
and Lopresti, Daniel",
title="IndicDLP: A Foundational Dataset for Multi-lingual and Multi-domain Document Layout Parsing",
booktitle="Document Analysis and Recognition -- ICDAR 2025",
year="2026",
publisher="Springer Nature Switzerland",
address="Cham",
pages="23--39",
abstract="Document layout analysis is essential for downstream tasks such as information retrieval, extraction, OCR, and digitization. However, existing large-scale datasets like PubLayNet and DocBank lack fine-grained region labels and multilingual diversity, making them insufficient for representing complex document layouts. Human-annotated datasets such as {\$}{\$}M^{\{}6{\}}Doc{\$}{\$}M6Doc and {\$}{\$}{\backslash}text {\{}D{\}}^{\{}4{\}}{\backslash}text {\{}LA{\}}{\$}{\$}D4LA offer richer labels and greater domain diversity, but are too small to train robust models and lack adequate multilingual coverage. This gap is especially pronounced for Indic documents, which encompass diverse scripts yet remain underrepresented in current datasets, further limiting progress in this space. To address these shortcomings, we introduce IndicDLP, a large-scale foundational document layout dataset spanning 11 representative Indic languages alongside English and 12 common document domains. Additionally, we curate UED-mini, a dataset derived from DocLayNet and {\$}{\$}M^{\{}6{\}}Doc{\$}{\$}M6Doc, to enhance pretraining and provide a solid foundation for Indic layout models. Our experiments demonstrate that fine-tuning existing English models on IndicDLP significantly boosts performance, validating its effectiveness. Moreover, models trained on IndicDLP generalize well beyond Indic layouts, making it a valuable resource for document digitization. This work bridges gaps in scale, diversity, and annotation granularity, driving inclusive and efficient document understanding.",
isbn="978-3-032-04614-7"
}
Acknowledgements
Select a language to see the list of contributors.
We would like to acknowledge the support from Indian Institute of Technology, Madras, India and International Institute of Information Technology Hyderabad, India.